Is Web Scraping Legal? Ethical Data Collection Guide 2026
Clura Team
Is web scraping legal? The short answer is yes — when you are dealing with publicly available data. Scraping public product prices, business listings, news headlines, or open social media posts is generally considered legal and has been upheld in major court rulings. The legal risk begins the moment you cross into private data, bypass authentication systems, or violate a website’s Terms of Service.
Think of it this way: you can take a photo of a building from a public sidewalk — no problem. But if you hop the fence and start snapping photos through the windows, you have crossed a serious line. The same principle applies to web scraping. This guide breaks down the key US laws, global privacy regulations, landmark court cases, and a practical compliance checklist so you can scrape with confidence.
Scrape Public Data Ethically with an AI-Powered Tool
Clura is built for ethical, responsible web scraping — collecting only publicly available data with built-in best practices. Explore prebuilt templates for compliant data collection workflows.
Add to Chrome — Free →What Really Decides if Scraping Is Legal?
The legality of web scraping hinges on two questions courts focus on: what data are you collecting (public vs. private), and how are you collecting it (respecting or bypassing access controls) — not on the technology itself.
Web scraping is a tool, like a hammer. The tool itself is not the problem — it is all about how you use it. When courts look at web scraping cases, they are not debating the technology. They focus on what data is being collected and how it is being accessed.
The Public vs. Private Data Divide
- Public data: product descriptions, stock prices, news headlines, public business listings — generally safe to scrape
- Private data: anything behind a password, paywall, or access control — scraping this is a clear legal no-go
- Personal data: names, emails, phone numbers — requires extra caution under GDPR and CCPA even if publicly posted
| Activity | Generally Legal | High Legal Risk |
|---|---|---|
| Data Type | Public, non-copyrighted data (prices, stock data) | Data from behind a login, paywall, or CAPTCHA |
| Website Rules | Adhering to robots.txt directives | Ignoring robots.txt or violating Terms of Service |
| Scraping Rate | Reasonable rate that does not impact server performance | Overwhelming a site with rapid requests causing DoS effect |
| Data Usage | Research, market analysis, personal projects | Reselling copyrighted content or using personal data without consent |
| Privacy | Anonymous, non-personal information | Scraping personally identifiable information (PII) |
The Core US Scraping Laws Explained
Web scraping in the US is primarily governed by three legal frameworks: the Computer Fraud and Abuse Act (CFAA), which prohibits bypassing technical barriers to access data; the DMCA, which protects copyrighted creative works; and trespass to chattels, which covers aggressive scraping that damages server infrastructure.
The Computer Fraud and Abuse Act (CFAA)
The CFAA is the main law in almost every scraping lawsuit. Written in the 1980s as an anti-hacking law, its core prohibition is accessing computer systems “without authorization.” Recent court rulings have significantly narrowed this: the consensus now is that the CFAA does not apply to scraping publicly available information. If you do not need a password and you are not bypassing a technical barrier to see the data, you are almost certainly not violating the CFAA.
For a company to bring a successful CFAA claim, they usually have to prove a scraper accessed a system without authorization AND caused at least $5,000 in damages. Courts have shifted their focus to whether technical barriers were broken, not just whether a site’s Terms of Service were ignored.
The Digital Millennium Copyright Act (DMCA)
The DMCA protects copyrighted material. Scraping factual data — product prices, stock levels, business names — and transforming it for analysis is almost always considered fair use. Trouble arises if you scrape creative articles, photos, or videos and republish them word-for-word. The rule: focus on extracting factual data, not republishing someone else’s creative work.
Trespass to Chattels
This old common law concept can apply when your scraping is so aggressive it actually harms a server — slowing it to a crawl or crashing it for real users. Think of it like sending a thousand robots into a retail store, blocking aisles so actual customers cannot get in. The lesson: scrape responsibly with polite, reasonable request rates and never intentionally disrupt a website’s service.
Navigating Global Data Privacy Laws Like GDPR
GDPR applies to anyone collecting data about EU residents — regardless of where your company is based — and classifies a wide range of information as ‘personal data,’ meaning that scraping personal information of EU residents without lawful basis is a direct violation even if that information is publicly posted.
If your scraping operations pull data from anywhere in the world, you must think globally. GDPR applies to you if you collect data about anyone located in the EU — it does not matter if your company is based in California. Since GDPR took effect in 2018, it has resulted in over 1,000 fines totaling more than €1 billion.
What GDPR Calls “Personal Data”
- Direct identifiers: names, email addresses, phone numbers, home addresses
- Indirect identifiers: IP addresses, location data, device IDs and cookie identifiers
- Special categories: race, political opinions, religious beliefs, health data
GDPR in Action: Two Real-World Scenarios
High-risk: scraping names and email addresses from German developer job sites to build a sales prospecting list — collecting personal data without consent for outreach purposes — is almost certainly a GDPR violation. Low-risk: scraping the same job board for anonymous aggregated data like job titles, required skills, city names, and salary ranges — deliberately avoiding anything that identifies a specific person — is a much safer, compliant activity.
GDPR’s core message is simple: just because personal data is public does not mean it is a free-for-all. Someone making their job history public on LinkedIn did so to connect with recruiters, not so a company could dump it into a sales database without asking.
Landmark Court Cases That Wrote the Rules
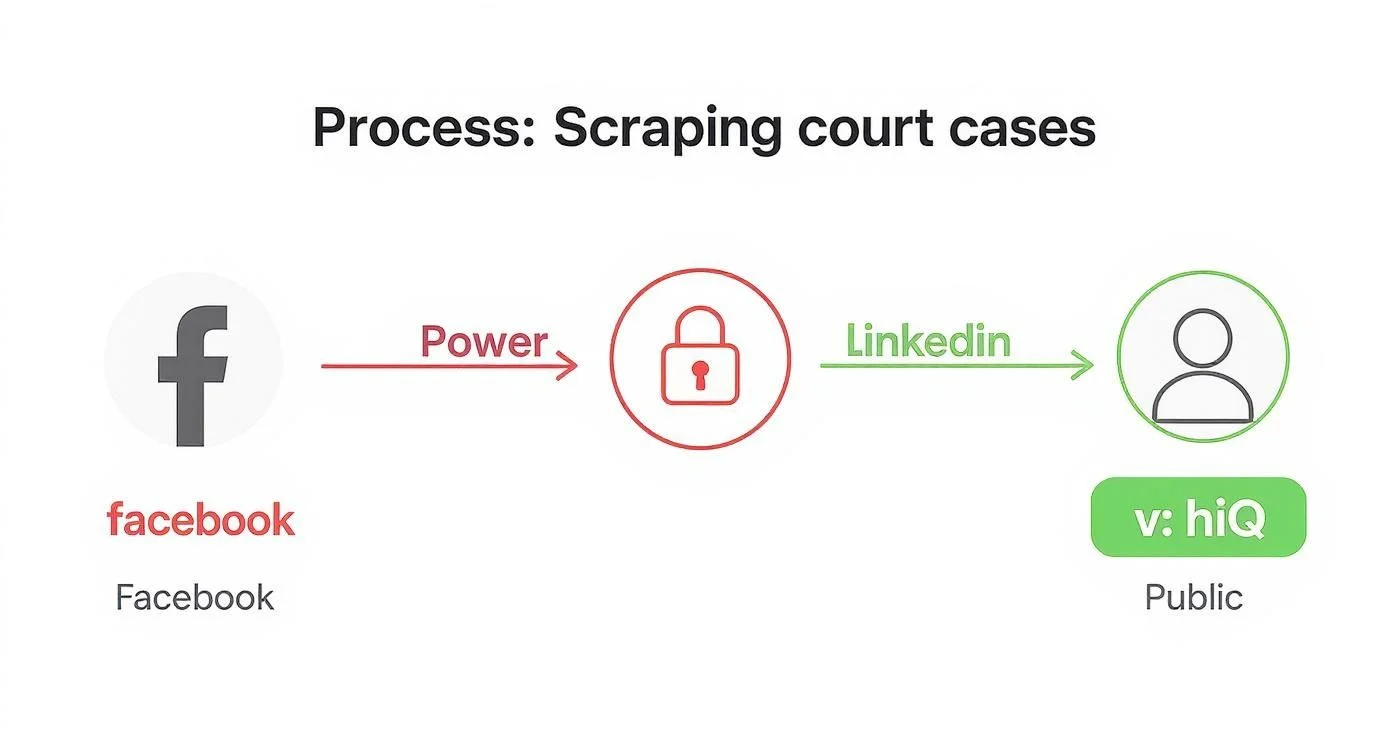
Two landmark cases define the legal boundaries of web scraping: hiQ Labs v. LinkedIn established that the CFAA does not apply to publicly accessible websites, while Facebook v. Power Ventures confirmed that accessing data from behind a login wall without platform permission is a clear CFAA violation.
hiQ Labs vs. LinkedIn: The Fight for Public Data
hiQ Labs scraped public LinkedIn profiles to provide workforce intelligence — predicting which employees might leave. All the data was publicly visible without a LinkedIn account. In 2017, LinkedIn sent a cease-and-desist. hiQ fought back, arguing scraping public data cannot be “unauthorized access” under an anti-hacking law. The Ninth Circuit Court agreed: the CFAA does not apply to publicly accessible websites. This set a powerful precedent that data intentionally made public is generally fair game for scraping.
“Giving companies like LinkedIn free rein to decide who can collect and use data risks the possible creation of information monopolies that would disserve the public interest.” — Ninth Circuit Court, hiQ v. LinkedIn
Facebook vs. Power Ventures: The Cautionary Tale
Power Ventures built a social media aggregator dashboard by scraping user data from Facebook accounts — going behind the login wall using users’ own credentials to pull private profile info, photos, and messages. Facebook sued and the court came down hard: accessing data from behind a password-protected system without the platform owner’s permission is a slam-dunk CFAA violation. Bypassing any authentication barrier is a textbook case of exceeding authorized access.
Scrape Ethically with a Compliant AI Tool
Clura is designed for responsible, ethical data collection — focusing on publicly available information with built-in rate limiting and best practices. Start collecting compliant datasets today.
Add to Chrome — Free →Your Checklist for Compliant Web Scraping
A compliant web scraping project starts with checking the target site’s robots.txt and Terms of Service, confirms you are only collecting public non-personal factual data, and uses a polite scraping rate with an honest User-Agent string that identifies your bot.
| Compliance Step | Action Required | Why It Matters |
|---|---|---|
| Review Site Policies | Read robots.txt and Terms of Service | Shows good faith and respect for explicit rules on automated access |
| Assess Data Type | Confirm only public, non-copyrighted, factual data | Avoids copyright infringement and privacy violations (PII, GDPR, CCPA) |
| Verify Access Method | Ensure data requires no login, password, or CAPTCHA | Bypassing authentication is the clearest legal no-go zone |
| Set Scraping Rate | Implement delays between requests to mimic human behavior | Prevents overloading the server, which can be seen as a DoS attack |
| Identify Your Bot | Use a descriptive User-Agent with contact information | Sign of good faith and transparency, allows site admins to reach you |
| Check for an API | Look for an official API before scraping | API is the approved, most stable, legally safest data access method |
| Schedule Off-Peak | Run scraping jobs during low-traffic hours (e.g., overnight) | Minimizes performance impact and reduces likelihood of detection |
Following this checklist is not just about legal compliance — it is about building a reputation as a responsible data professional and ensuring your data pipelines are sustainable long-term. Our guide on how to extract data from websites dives into best practices for playing by the rules.
Frequently Asked Questions
Can I ignore a website’s Terms of Service when scraping?
You can, but it carries real risk. While scraping public data in violation of a site’s ToS is not a federal crime under recent CFAA rulings, it can be treated as a breach of contract, giving the website owner grounds for a civil lawsuit. The safest approach is to always read the ToS and respect any rules against automated data collection.
What is the difference between web scraping and web crawling?
Crawling is exploring — following links from page to page to discover and index content, which is what search engine bots do. Scraping is mining — a focused mission to extract specific pieces of information from a page, like product prices, contact details, or stock numbers. A crawler finds the map; a scraper digs for the treasure.
Are some industries riskier to scrape than others?
Yes. Social media, healthcare, and finance carry higher risk because they are full of sensitive personal and proprietary information. E-commerce (public product prices), real estate (public listings), and news aggregation (headlines) are generally much safer — the data is already publicly available and not sensitive. Your risk is directly proportional to the data’s sensitivity.
Is it legal to scrape for a personal project?
Scraping data for personal use — tracking sports stats, monitoring prices for a passion project — is typically very low risk. The legal heat is way down when you are not trying to monetize the data. The golden rules still apply: respect robots.txt, avoid personal data, and scrape at a reasonable rate.
Conclusion
The legal landscape for web scraping is clearer than many people realize. Scraping publicly available, factual, non-personal data — product prices, business listings, public posts — is generally legal and has been repeatedly upheld in court. The risk only escalates when you bypass authentication, collect personal data without legal basis, or aggressively hammer servers.
The two landmark cases — hiQ v. LinkedIn and Facebook v. Power Ventures — draw a clear map: public data is fair game, private data behind login walls is off-limits, and how you scrape matters as much as what you scrape.
Use the compliance checklist in this guide before every project: check robots.txt and ToS, confirm you are collecting only public factual data, set a polite scraping rate, and identify your bot honestly. These habits protect you legally and build your reputation as a responsible data professional.
Explore related guides:
- How to Extract Data from Websites —
- Web Scraping for Lead Generation —
- Data Scraping Chrome Extension Guide —
Scrape Responsibly with an AI-Powered No-Code Tool
Clura is built for ethical, compliant data collection — focusing on publicly available information with built-in best practices. Explore prebuilt templates for responsible scraping workflows.
Add to Chrome — Free →About the Author